




Hadoop分布式平台环境
前提准备
操作系统:CentOS7 机器:虚拟机3台,(master 192.168.1.201, slave1 192.168.1.202, slave2 192.168.1.203) JDK:1.8.0_121(jdk-8u221-linux-x64.tar.gz) Hadoop:2.9.2(http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz)
安装VMware和三台centoos
这儿我就不细分了,网上教程比我写的好的很多
起步
1、 在vmware安装好linux虚拟机后 重启虚拟机 在root权限的根目录下 修改IP地址 vi /etc/sysconfig/network-scripts/ifcfg-ens33
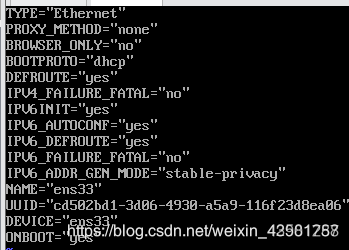
2、 修改BOOTPROTO=“static” 并为其添加IP和网关 IPADDR=“需要配置的IP地址” GATEWAY=“192.168.1.2” DNS1=“8.8.8.8”
3、 !wq保存后 执行:service network restart在这里插入图片描述 如果出现错误,执行reboot,重启虚拟机 修改主机名

4、 修改主机名:vi /etc/sysconfig/network
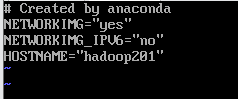
在hosts里面添加内容

vi /etc/hosts 并重启设备,重启后,查看主机名,已经修改成功
5、 修改window10的hosts文件 (1)进入C:WindowsSystem32driversetc路径 (2)打开hosts文件并添加如下内容 192.168.1.201 hadoop201 192.168.1.202 hadoop202 192.168.1.203 hadoop203
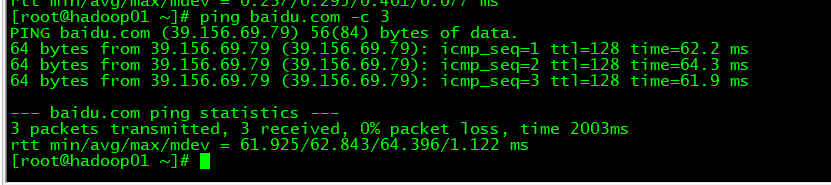
6、 关闭防火墙,并在命令里面ping虚拟机 防火墙基本语法: firewall-cmd --state (功能描述:查看防火墙状态) Service firewalld restart 重启 Service firewalld start 开启 Service firewalld stop 关闭 永久关闭: systemctl stop firewalld.service停止 systemctl disable firewalld.service禁止开机启动
ping -c 3 slave1 (※ 3表示发送 3 个数据包)
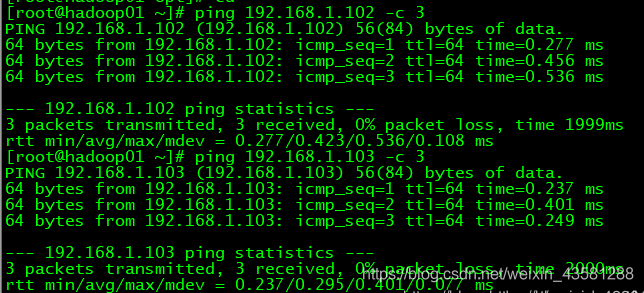
接下来既可以快乐的使用xshell敲代码了
jdk环境(我这儿用的1.8)
1、卸载现有jdk
查询是否安装java软件:rpm -qa|grep java 如果安装的版本低于1.7,卸载该jdk:rpm -e 软件包
2、传输文件
opt下创建两个文件夹 mkdir software mkdir module
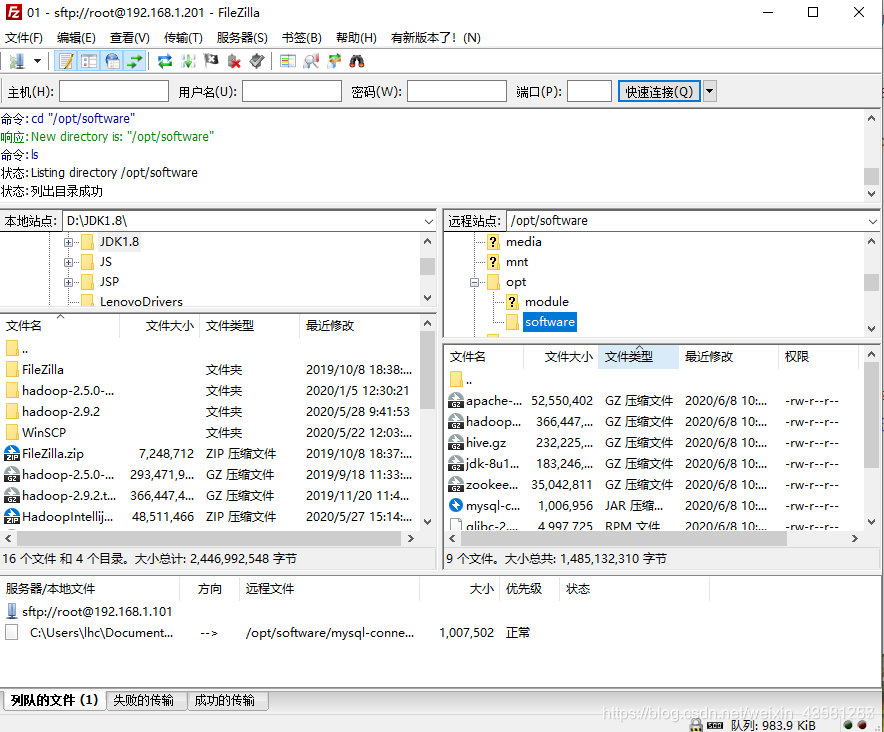
在software下 tar -zxvf jdk-8u121-linux-x64.gz -C /opt/module/ 依次解压 tar -xvf mysql文件名 复制路径
/opt/module/jdk1.8.0_121 /opt/module/hadoop-2.9.2 配置全局路径 vi /etc/profile
让修改后的文件生效: source /etc/profile
以上就是配置好的Java环境和Hadoop环境变量。接下来我们再去配置好Hadoop的其他环境。
core-site.xml
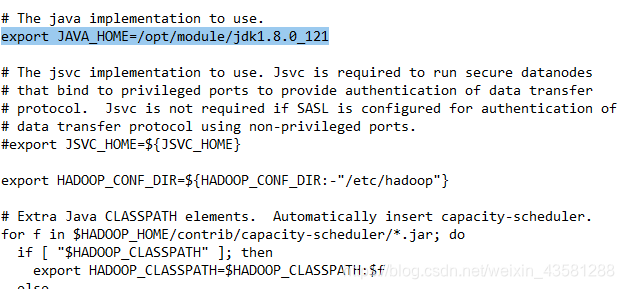
hadoop-env.sh
hdfs-site.xml
Slaves(配置哪几台是datanode) 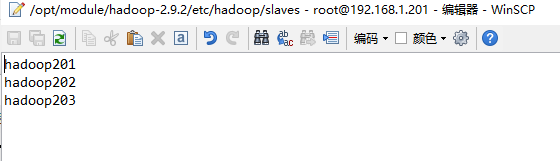 yarn-env.sh
yarn-env.sh
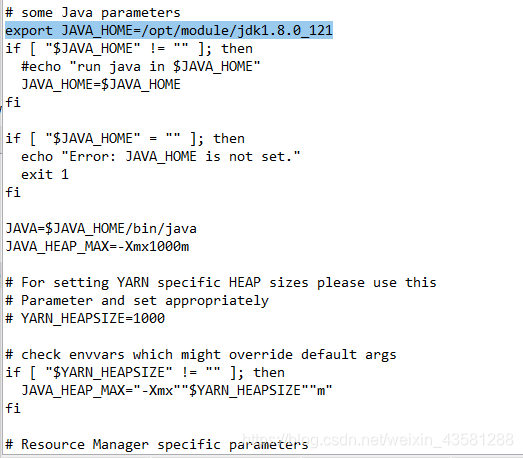
yarn-site.xml
mapred-env.sh
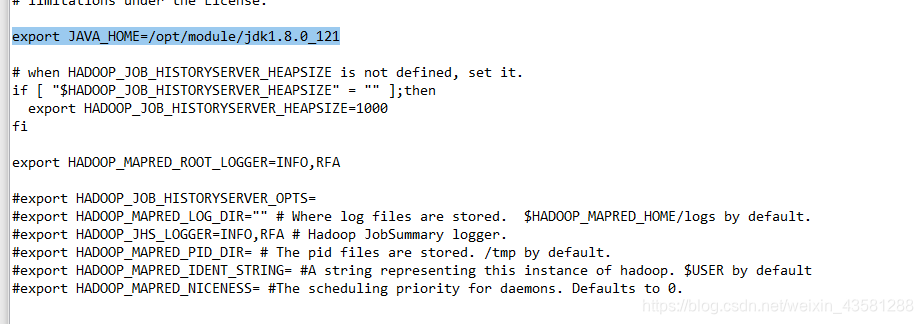 mapred-site.xml
mapred-site.xml
在vmware中对配置好的虚拟机进行克隆002,003(注意修改主机名和IP) ssh免密码登录 每台机器执行: ssh-keygen -t rsa
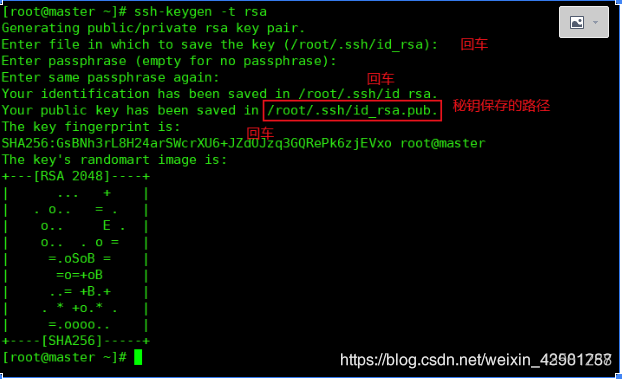
把 hadoop201 节点上的 authorized_keys 钥发送到其他节点 hadoop201 执行命令,生成 authorized_keys 文件:

把 authorized_keys 发送到 hadoop202 hadoop203 节点上
在hadoop201 节点测试免密码登录 hadoop202、hadoop203 命令:ssh 机器名

启动 Hadoop 集群 1.格式化 namenode 节点 只需要在 master 机器上执行就好 hdfs namenode -format 2. 启动集群:在master上执行 start-all.sh 启动时候发现resourcemanager没有起来关闭防火墙输入以下代码 sbin/yarn-daemon.sh start resourcemanager

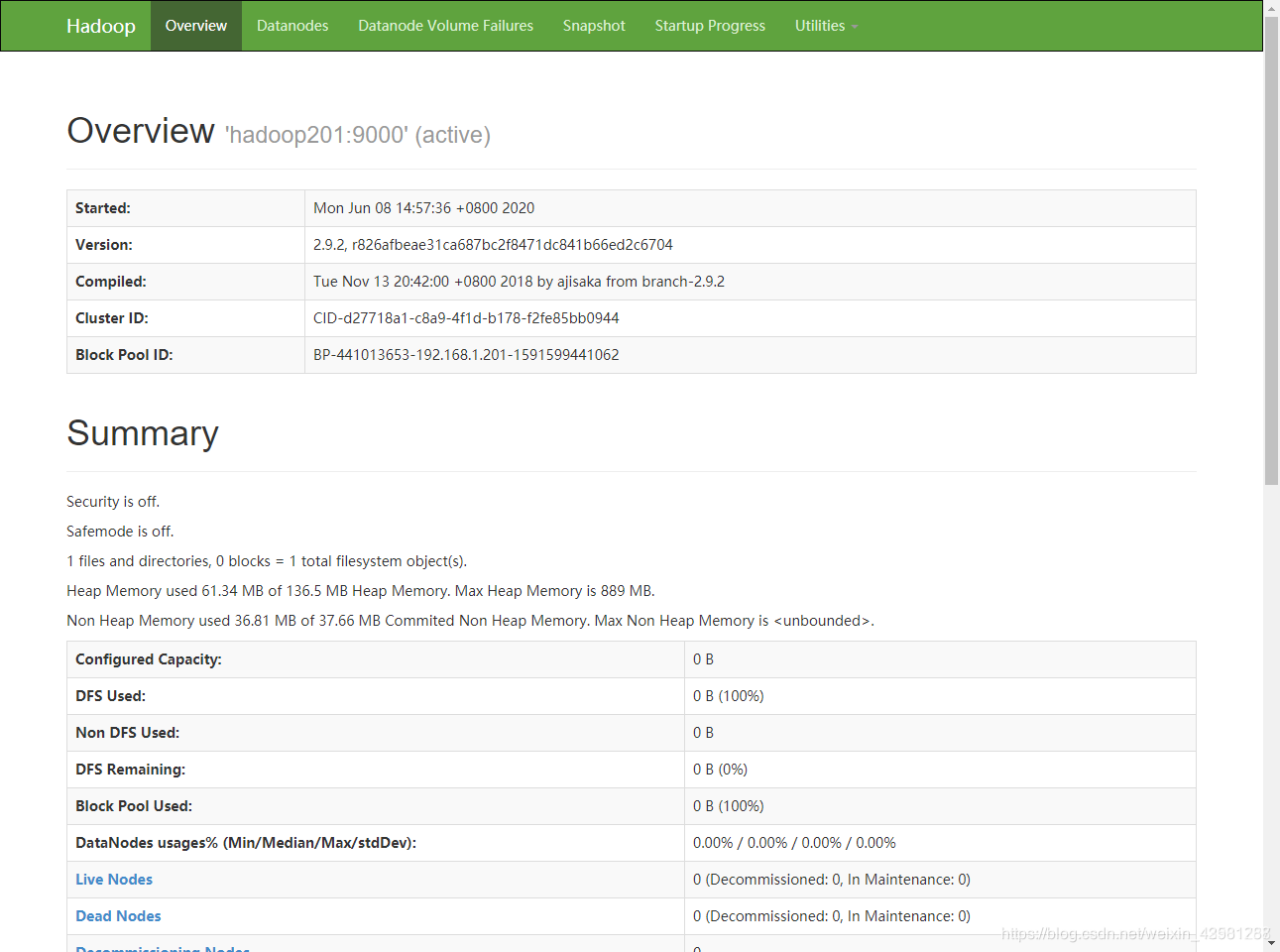
在浏览器输入192.168.1.201:50070
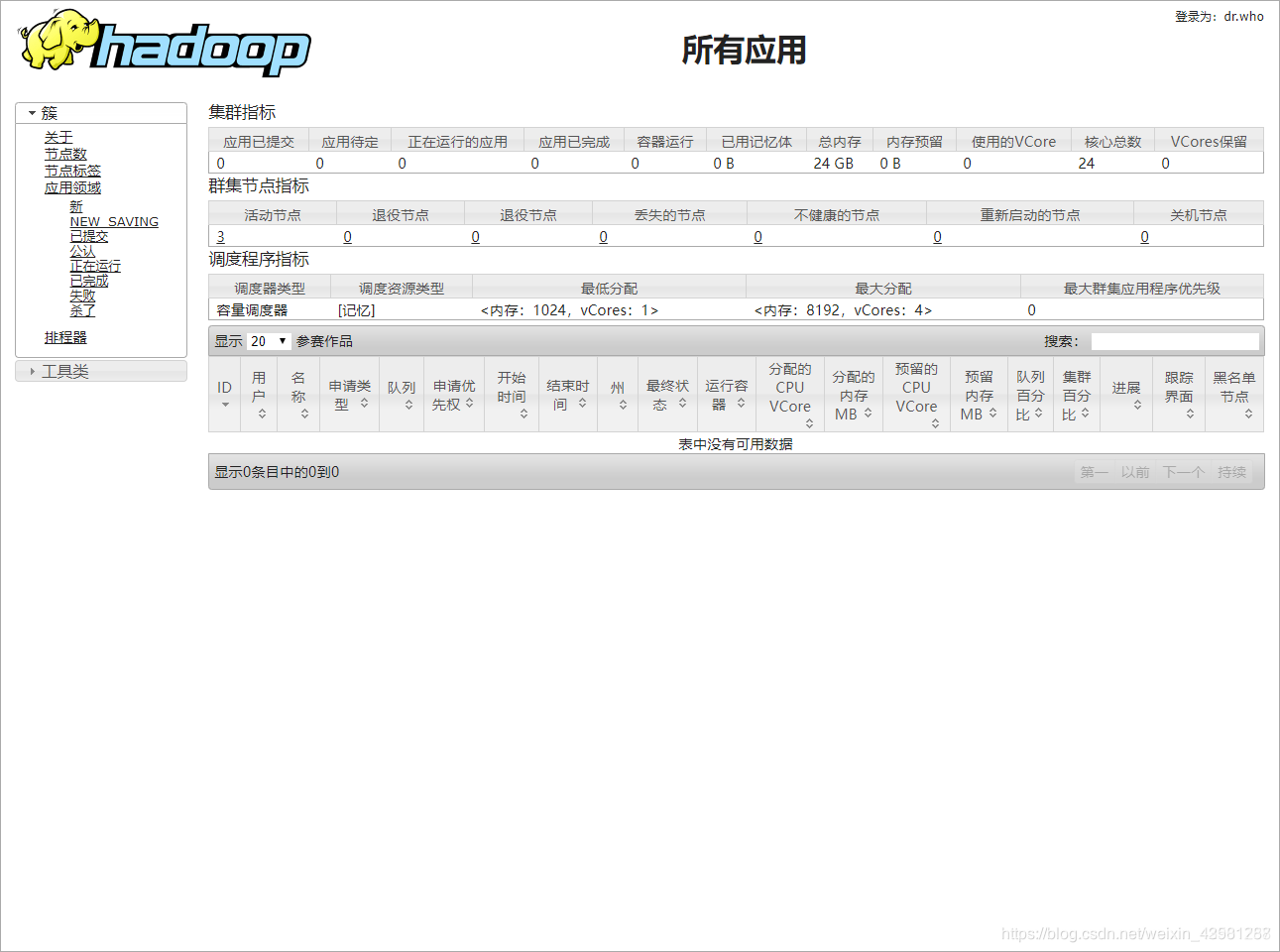
在浏览器输入192.168.1.202:8088
完美搞定!
hive,flume,mysql,sqoop安装包和安装步骤在链接里面 链接:https://pan.baidu.com/s/1C3e4FpeX-RQ-9GVak6rekA 提取码:sed6
flume环境
安装好文件以后
flume配置 配置flie-hdfs.conf文件
分析网页
点击进入网页 我们先来看看网页构造。再来分析思路: 由于我们需要的大数据岗位的分布数据,所以我们就直接搜索条件,分析大数据岗位在全国的一个分布情况。 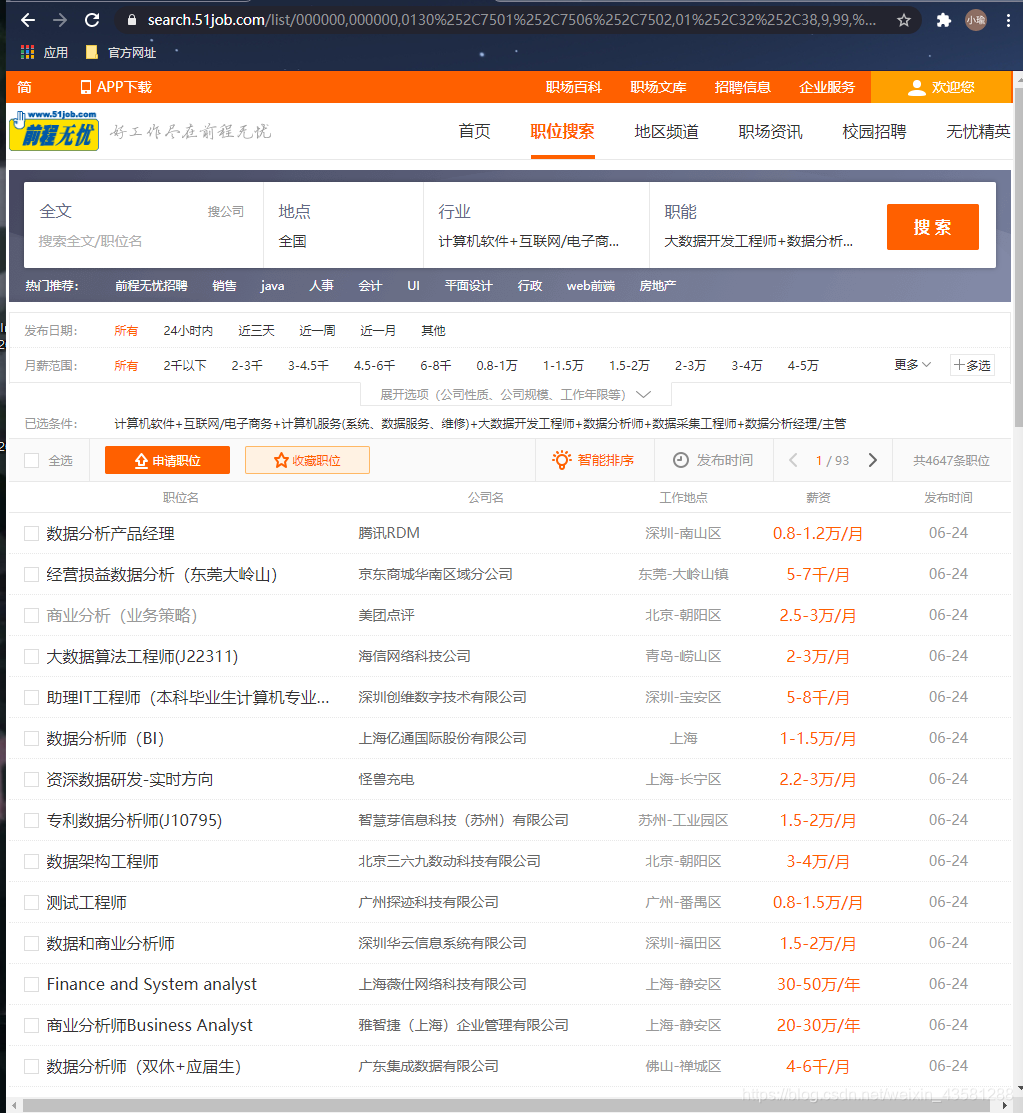 我的思路是,既然需要字段,而且这个页面上的所有字段并没有我们需要的全部,那我们就需要进入到每一个网址里面去分析我们的字段。先来看看进去后是什么样子。
我的思路是,既然需要字段,而且这个页面上的所有字段并没有我们需要的全部,那我们就需要进入到每一个网址里面去分析我们的字段。先来看看进去后是什么样子。 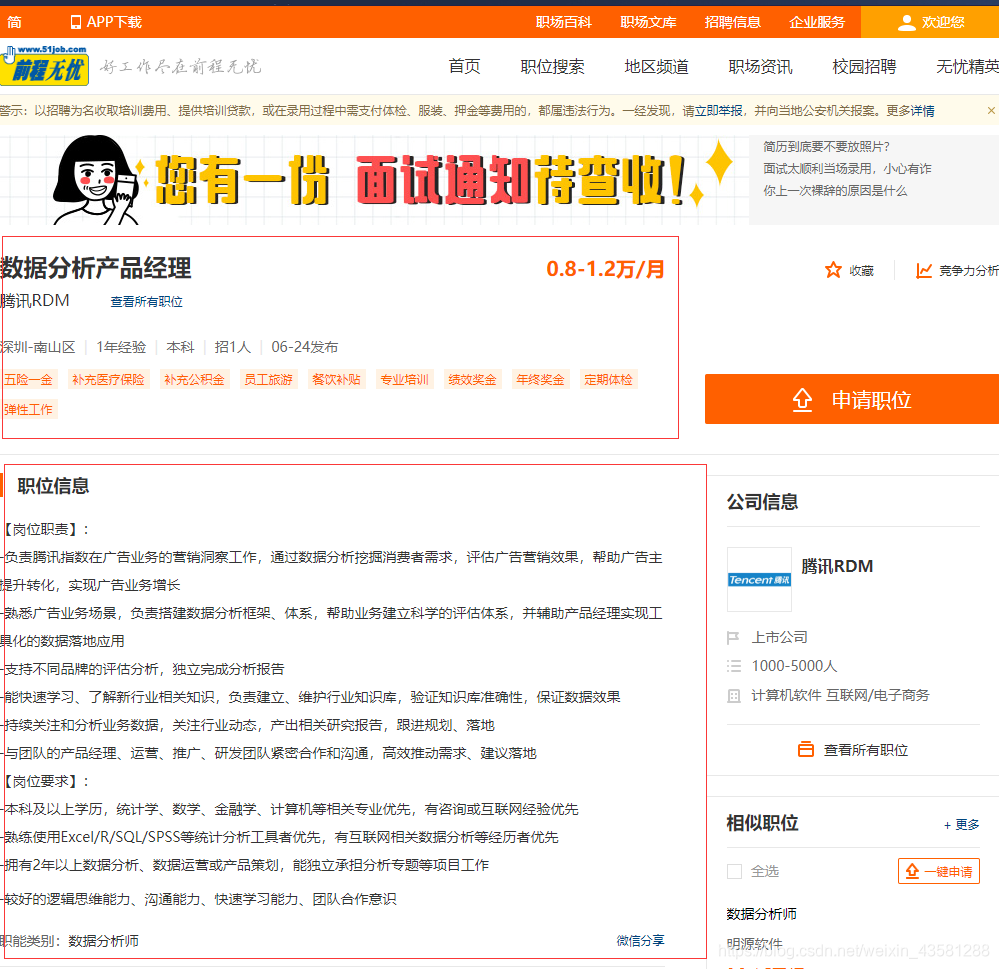 我们需要的字段都在这里面了,所以,我们就可以开始动手写代码了。
我们需要的字段都在这里面了,所以,我们就可以开始动手写代码了。
实现代码
抓取全部岗位的网址
我们之前说过,要进入到每一个网址去,那么就必然需要每一个进去的入口,而这个入口就是这个: 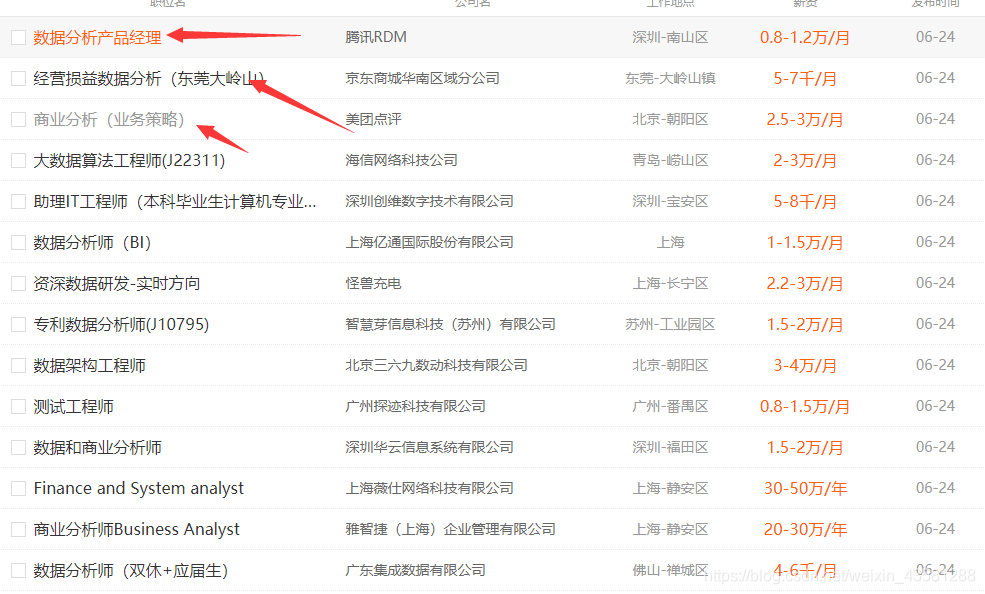 新建一个爬虫项目:
新建一个爬虫项目:
然后打开我们的项目,进入瞅瞅会发现啥都没有,我们再cd到我们的项目里面去开始一个爬虫项目
当然,这后边的网址就是你要爬取的网址。
首先在开始敲代码之前,还是要设置一下我们的配置文件settings.py中写上我们的配置信息:
然后再去我们的pipelines.py中开启我们的爬虫保存工作
定义好pipelines.py之后,我们还需要去items.py中去定义好我们需要爬取的字段,用来向pipelines.py中传输数据