

目录

一、深层残差模型
1. 卷积批归一化块
2. 残差块
3. 残差网络
4. 训练
二、浅层网络模型
1. 残差块
2. 残差网络
3. 训练:
三、改进版本
四、总结
在深度学习中,一般来说,神经网络层数越多,网络结构也就越复杂,对复杂特征的表示能力就更强,对于复杂的数据集,就有更强的预测能力。但是在实际上,增加神经网络的层数后,训练误差往往不降反升。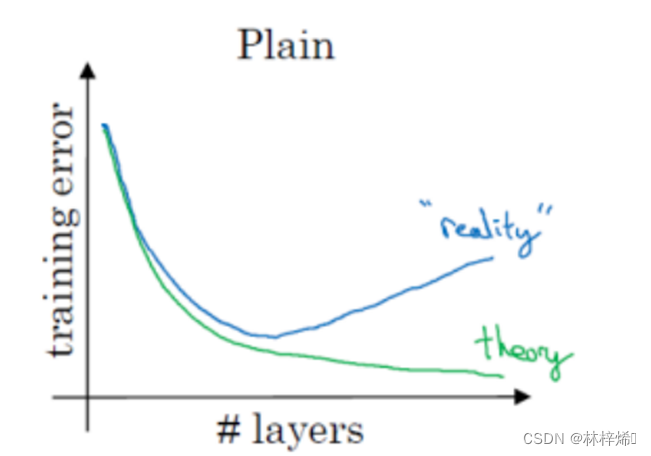
如上图我们理论上期望的曲线是绿色的“theory”,训练误差随网络层次的加深而不断降低。然而实践表明,实际的曲线应该是蓝色的曲线“reality”,在网络层次达到一定深度后,训练误差不但不会降低,反而会逐渐上升。
这是因为单纯的提示网络的深度会导致梯度在反向传播中损失信息,也就是梯度信息在从顶层反向传播到底层时会逐渐的消失,导致顶层参数更新的快,但底层几乎不会更新,但某一层停止学习,则信号就会在这一层直接消失,导致信息无法传递到底层,从而造成梯度消失的现象。此外,在深层的神经网络中如果某一层与原模型产生了较大的偏差,预测结果反而不如原模型,后续的网络会不断加剧这个问题,模型一直往错误的方向更新,导致“负优化”,如下图。
为了解决上面的问题,我们可以使用残差网络ResNet,ResNet最初就是为了解决“负优化”问题的,但同时它也能解决梯度信息在反向传播过程中逐渐消失的问题。
在学习残差块之前我们需要先了解BatchNorm层,这个层是用于对输出数据进行标准化处理的,以次来保证后续网络接收的输入数据是进行标准化处理后的。
虽然一般我们在输入数据时都会对数据进行标准化处理,但是在神经网络中,每层的参数都是在不断更新的,即使第一层已经处理过,在不断更新参数后数据中仍然可能会出现不稳定的数值,导致模型很难收敛,因此在每一层操作过后通常都需要进行标准化处理,常用的方法是批归一化(Batch Normalization),下面我们就定义一个卷积批归一化块,其中包含卷积层和BatchNorm层。
上述代码使用nn.Conv2D类来创建卷积层,输入输入输出通道数、卷积核大小、步幅、填充等参数来创建一个二维的卷积层。而BatchNorm则使用paddle.nn.BatchNorm2D来创建,输入的参数是模型的输出通道数(实际上就是卷积核的输出通道数)。
前向传播就是使用上面定义的卷积层和BatchNorm层首先进行卷积操作,然后对输出进行批量归一化操作,act是网络最后进行的操作,一般是激活函数,根据输入的act调用不同的激活函数(leaky是在relu基础上改进的激活函数,可以缓解ReLU中可能出现的神经元“死亡”问题。)
接下来就是定义残差块了,在此之前,我们先了解一下什么是残差块,以及它的实现步骤。
在一般的卷积神经网络中,网络的输出是输入数据的映射,即y=F(x),也就是输入数据进行卷积和激活函数后的输出,如下图。
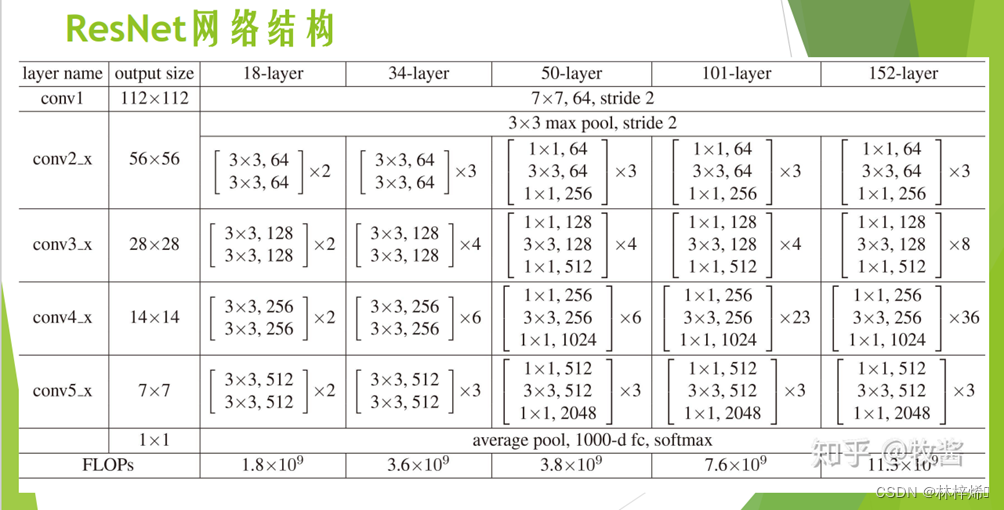
而在残差网络中,输出的不单单是映射输出,而是y=F(x)+x,是输入数据的映射与输入数据之和,此时网络不是直接学习输出特征y的表示,而是学习残差,残差就是F(x),也就是y-x,即输出与输入之间的残差,如下图。
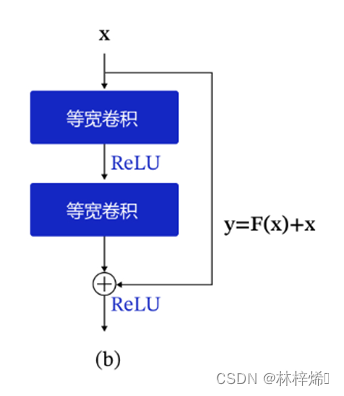
这样,每一层的网络都有输入与输出直连的旁路,也就相当于每一层都有与最顶层的损失直接对话的机会,这样损失就不会在自顶层向下反向传播时逐渐消失了。
在比较深层的网络中,复杂的参数通常导致非常高的计算复杂度,我们可以先将输入数据与1*1卷积核进行卷积运算来减少数据的通道数,因为每个通道都要进行一次卷积计算,减少数据的通道数就能显著减少计算的复杂度。
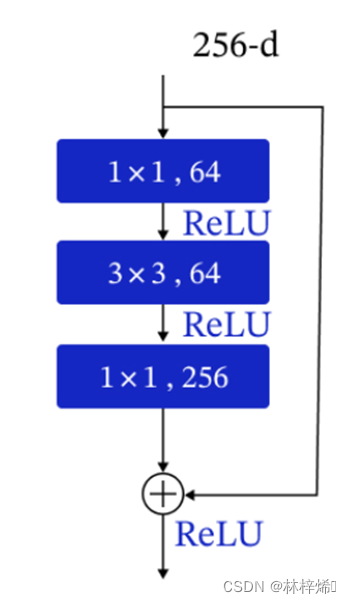
上图就是在进行卷积计算前先经过1*1卷积将通道数由256降低到64,进行卷积计算后,再进行一次1*1卷积将通道数恢复到256。
根据这个步骤,我们就可以定义残差块了,不过残差块中的卷积核的输出通道数与上图不一样。
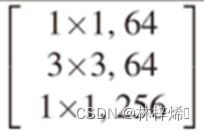
按照上图,残差块中首先进行一次1*1卷积,降低一倍通道数,然后进行3*3卷积,最后1*1卷积恢复通道数,不过这里不是直接恢复到输入的通道数,而是输入的两倍,在3*3卷积前降低了一倍的通道数,因此在最后一个1*1卷积核的通道数是输入的4倍。
上面的代码首先定义3个我们上面定义的卷积批归一化块,包含卷积、归一化、激活三个操作,第一个是1*1的卷积操作,用于减少通道数,降低计算复杂度,第二个块是正常的3*3的卷积操作提取数据特征,最后一个块是1*1卷积恢复通道数,如果此时输出结果与输入数据形状不相同的话需要对输入数据进行一次1*1卷积操作使其与conv2形状相同,否则无法将两个数组进行相加。前向传播的过程就是依次进行三次卷积批归一化操作,如果输入与最后卷积输出结果形状不同,再修改输入数据的形状,最后将输入数据与卷积输出结果相加得到此残差块的输出。
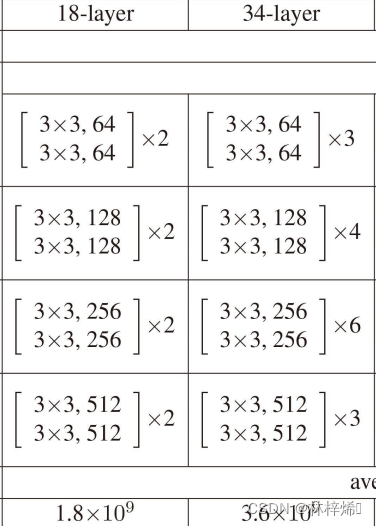
我们知道卷积网络就是多个卷积层、池化层与全连接层串联起来的网络,而残差网络也是类似的,残差网络是多个残差块串联起来的,这些残差块被分在不同的模块中,一共有4个模块,各个模块中各有几个一样的残差块,如下图展示了不同层数的残差网络各个模块的残存块和数量。
以50层为例,首先对输入进行7*7卷积,然后是3*3的最大池化层,接着就是4个模块,各个模块中的残差块各有3、4、6、3,各个残差块有各有3层卷积,最后再加一层全连接层,一共就是1+3*3+4*3+6*3+3*3=49个卷积层和1个全连接层,一共是50层。如下图。
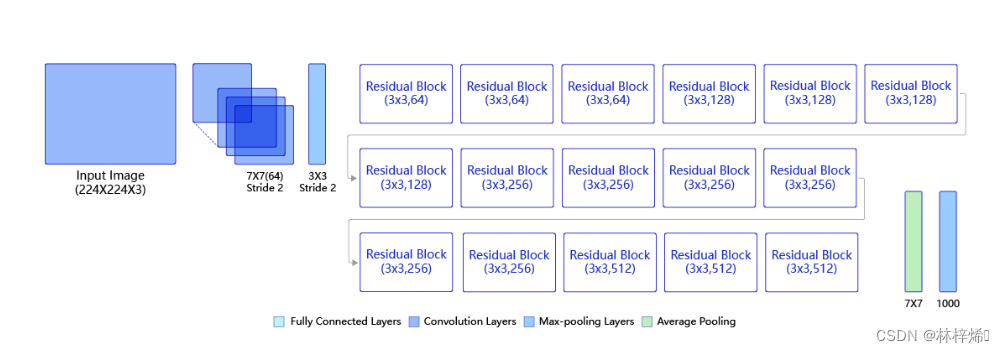
观察不同层数的ResNet网络结构,我们能发现50、101、152层在同一个模块中都是使用同样的残差块,各个模块的残差块的最后两维的形状也是相同的,只是输入输出通道不同,因此我们可以定义一个支持50、101、152层的模型,不同层数的网络只是模块中的残差块数量不同而已,其他都是一样的。
接下来我们设计一个支持50、101、152层网络的残差网络模型。
首先根据上图分别定义50、101、152层的4个模块中的残差块数量,保存在depth中。不同层数的网络只是模块中残差块的数量不同,各个模块里的残差块是相同的,因此我们只需要保存各个模块里的残差块数量就行了,不同层数的网络在同一个模块中都是使用同样残差块(仅针对50、101、152层网络而言,18、34层是没有1*1卷积操作的,因此残差块不同),而残差块都是1*1、3*3、1*1这三个卷积批归一化块组成,只是不同模块中输入输出通道数不同,我们可以将各个模块中的卷积输出通道数保存在num_filters中。
接下来首先定义7*7卷积,和3*3池化层,7*7卷积层使用的是之前我们定义的卷积批归一化块,池化层则使用nn.MaxPool2D,然后就是接下来的4个模块,根据depth中各个模块的数量在网络中添加残差块。残差块使用之前我们定义的BottleneckBlock类进行创建,卷积层的输出通道数就在num_filters中,再将残差块添加到bottleneck_block_list中。最后就是定义一层平均池化层和全连接层。
前向计算的过程就是依次通过各个层,首先是7*7卷积层和3*3池化层,接着是4个模块,4个模块中的残差块都在bottleneck_block_list中,直接从中依次取出残差块,传入输入数据进行计算,最后再通过一层平均池化层和全连接层out,输出结果。
飞浆开源框架支持高层API,高层API中支持paddle.vision.models接口,实现了对常用模型的封装,包括ResNet、VGG、MobileNet、LeNet等。我们尝试使用API中的ResNet50模型进行计算。
这里只是尝试调用一下ResNet50模型,输出结果没有意义,因此只打印输出的形状,ResNet50默认是1000分类,因此输出结果的形状是1*1000。
现在我们使用paddle.vision中的ResNet模型进行训练
训练结果:

这是在飞浆平台上训练的结果,训练的时间非常的长,快接近一个小时了。
我们也可以使用飞浆的API训练我们自己定义的模型:
由于训练时间实在太长,这里只截取5轮的训练结果,这是我在自己的电脑上训练的结果
第5轮训练结果:
上面只实现了深层网络的瓶颈架构,浅层的18和34层的模型没有实现,现在我们来实现一下这两个模型。
适用于浅层网络的基础版的ResNet,支持18层和34层,这两种模型的ResNet中残差块都是由两个3*3的卷积层构成。在实现这个模型前,首先需要先实现18层和34层所需的残差块,这两种模型的残差块都是一样的,只需要实现一个就好。
卷积批归一化层还是用之前的。

根据18、34层所用残差块可以定义残差块如下:
该类中定义了两层3*3卷积批归一化化块,第一层卷积批归一化块需要激活,但第二层不需要,因为激活是在与输出相加后进行的。为了防止最终计算的输出与输入不相同,导致无法相加,因此需要判断输入和输出的形状是否相同,如果不相同则需要使用1*1卷积改变输入数据的通道数使其与输出数据的通道数相同。前向计算就是依次经过两次卷积,最后再与输入相加,再激活得到最终结果。
接着是残差网络模型,根据下图定义18、34层的残差网络
这里还是只训练了5个周期
浅层网络学习的难度比较低,因此精度会比深层的好一些。
ResNet后续版本中作者将残差块里的“卷积、批量归一化和激活”结构改成了“批量归一化,激活和卷积”,这个改进很容易实现,只需要在卷积批归一化块中更改卷积、批量归一化和激活为批量归一化,激活和卷积就行了。
训练结果(5轮):

残差网络是通过将输出从输入的映射改为输入数据加上输入的映射,这样就从学习输出的特征y表示变为学习残差,这样就有一条旁路连接输入和输出,每一层都能直接与顶层的损失进行“对话”,以此解决了梯度在反向传播的过程中逐渐消失的问题。残差块是残差网络中的主要组成部分,残差块中的操作就是首先进行卷积再批归一化再激活,各种版本的残差网络都是分成几个模块,其中第2、3、4、5个模块中是多个残差块,根据层数的不同,各个模块中的残差块数量也有所不同,基础版的有18,34层的网络,每个残差块只进行两次3*3卷积,没有使用1*1卷积减少通道数,而深层网络中50,101,152层的网络,每个残差块进行三次卷积操作,第一层是1*1减少通道数,第二层是3*3卷积,第三层是1*1恢复通道数。
由于网络模型层数很多,训练的时间也是非常的长,50层的训练就要耗费接近一个小时的时间进行训练,多个版本训练过去时间要消耗非常多,为了节省时间,后面几个版本我只训练了5个周期。