


HDFS是Hadoop的底层分布式存储系统,是Hadoop分布式计算的底层基石,要使用Hadoop就必须学习HDFS的使用。本文介绍了为什么要使用HDFS、HDFS的基本使用、核心架构组成以及分布式可靠性保障机制。
HDFS全称为Hadoop Distributed File System,即为Hadoop提供的分布式文件系统,Hadoop底层的存储能力都是基于HDFS来提供,所以认为HDFS是整个Hadoop体系的底层核心基石。HDFS的特点是采用了低成本的硬件设计模式,具备很高的容错性,可以部署在价格低廉的普通服务器上,通过多台服务器组成HDFS集群从而提供分布式存储的能力。
1.1、为什么需要HDFS
为什么需要HDFS?一般来说普通的应用使用MySQL、Oracle甚至Redis这类数据库就可以满足数据的存储需求: 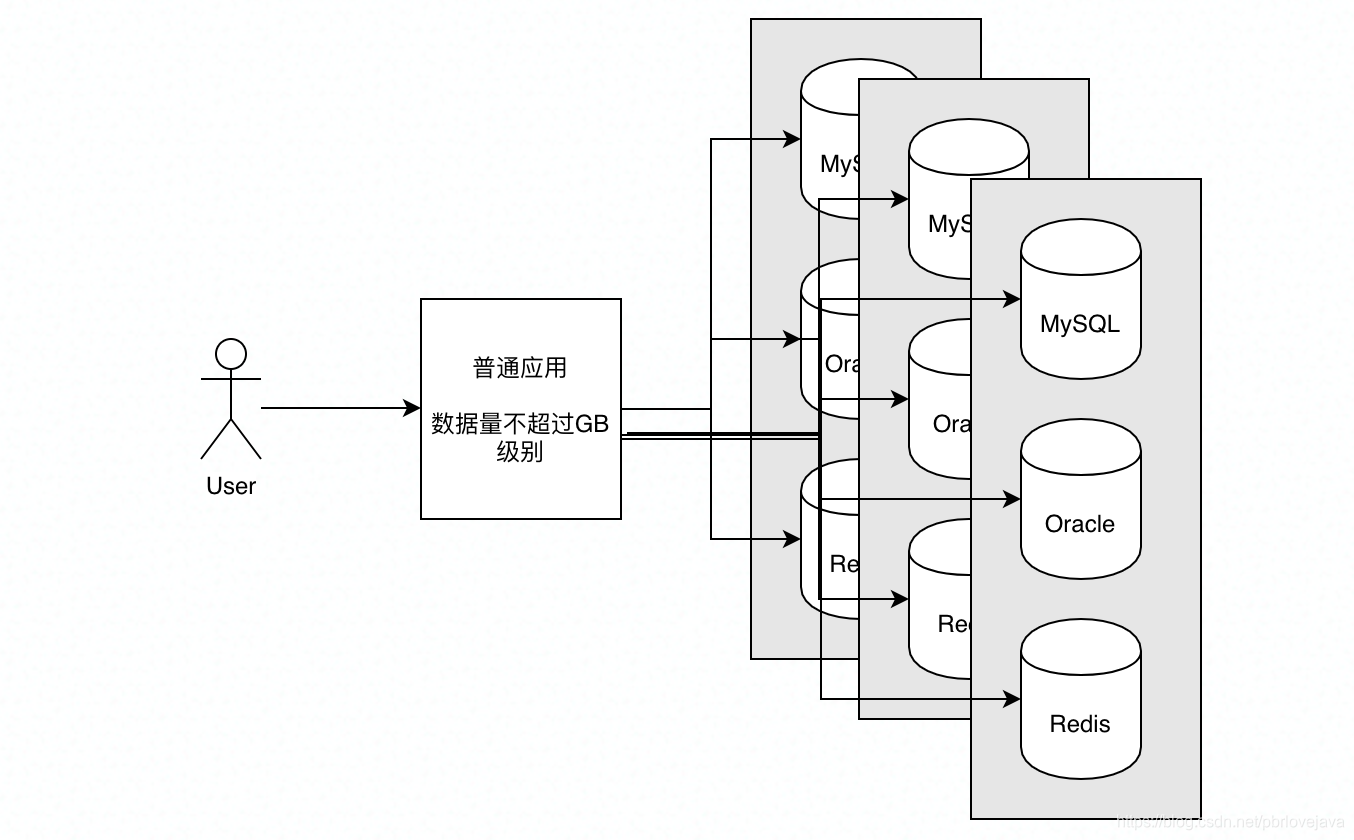
但是随着数据量越来越大,需要进行存储和分析的数据已经达到GB甚至TB级,那么如果仍然采用MySQL这类数据库进行存储,会十分占用存储资源,并且由于单表数据量过大, I/O的消耗也是巨大的,每次查询都需要很长时间,而且在复杂的数据分析时需要Join多个表,可能会引发系统的阻塞,所以在大数据量下(GB/TB级)不太建议使用MySQL这类数据库对数据进行存储。 那什么存储资源是廉价的、可拓展的呢?就是硬盘。硬盘作为计算机底层存储资源,由于其读写速度远不如内存的读写速度,所以十分廉价,假设一个廉价的服务器装上了500GB容量的硬盘,那么当我们要存储2TB容量的数据时,就可以采用4台500GB容量的服务器来对其分割后进行存储。如果采用这种方式存储数据,那么整体的数据存储成本就会比用MySQL这类数据库存储低得多,这就是HDFS的核心思想:数据切割+分布式存储。 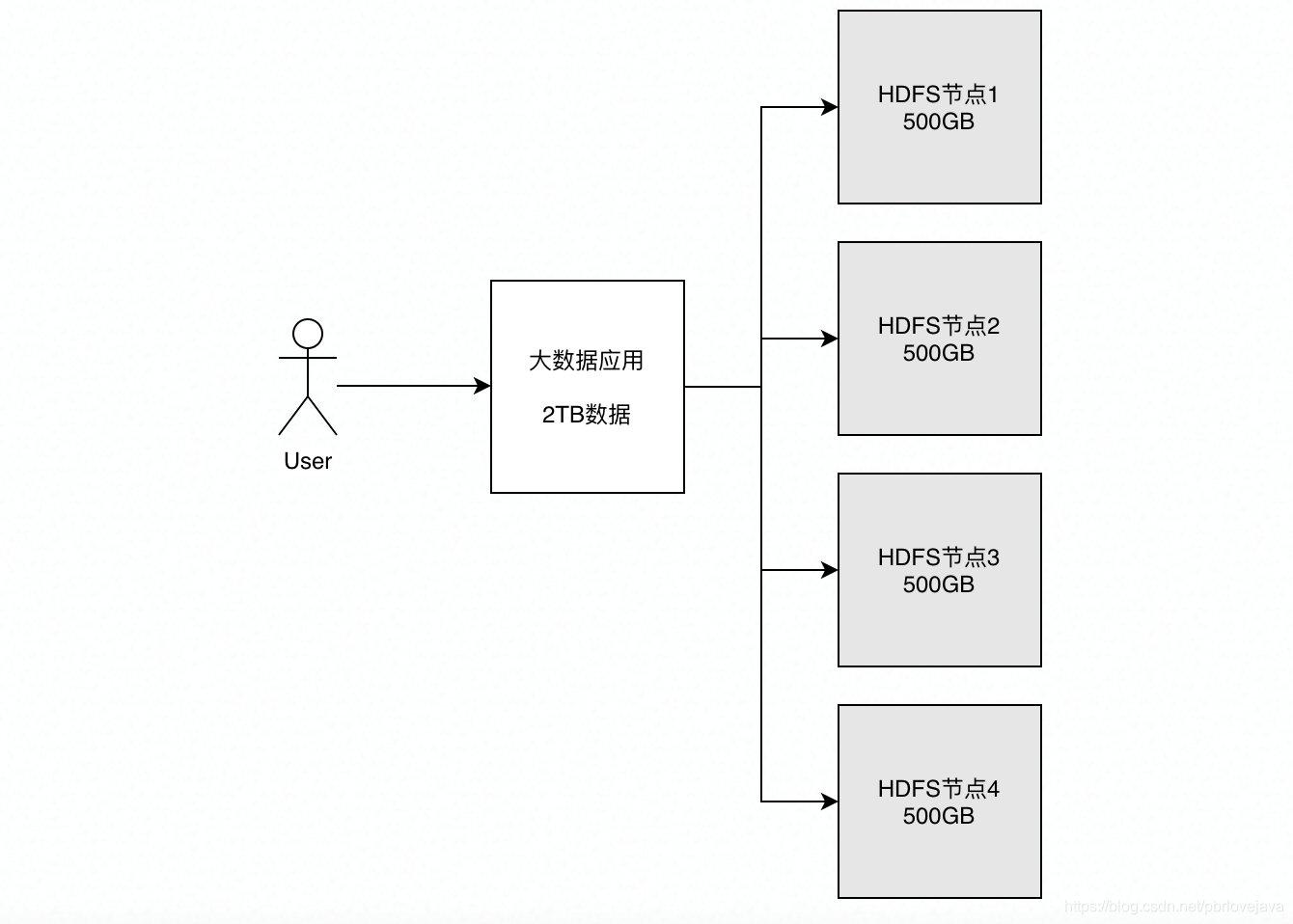
1.2、核心数据和行为数据
关于什么数据需要存储在HDFS中,不仅是要求数据有大的数量级,一般还要求其为行为数据。这里引入两个概念,分别是核心数据和行为数据,核心数据指的是系统正常运转和服务所需要的数据,比如在交易过程中的订单数据、物流数据等,缺少了核心数据系统将无法运转,这些核心数据一般存储在数据库中;而行为数据指的是在产生核心数据的这个过程中,附带产生的操作行为带来的数据,比如操作日志数据、操作过程数据等等,缺少了行为数据也不阻碍系统正常运转。
对于HDFS来说,主要是存储大量的行为数据,以辅助对核心数据的分析、用户操作的分析等等,从而利用好这些大数据对商业变现做出价值。
2.1、核心架构组件
HDFS的核心架构组件图如下,主要分为Client、NameNode、SecondaryNameNode、DataNode这四个核心组件。 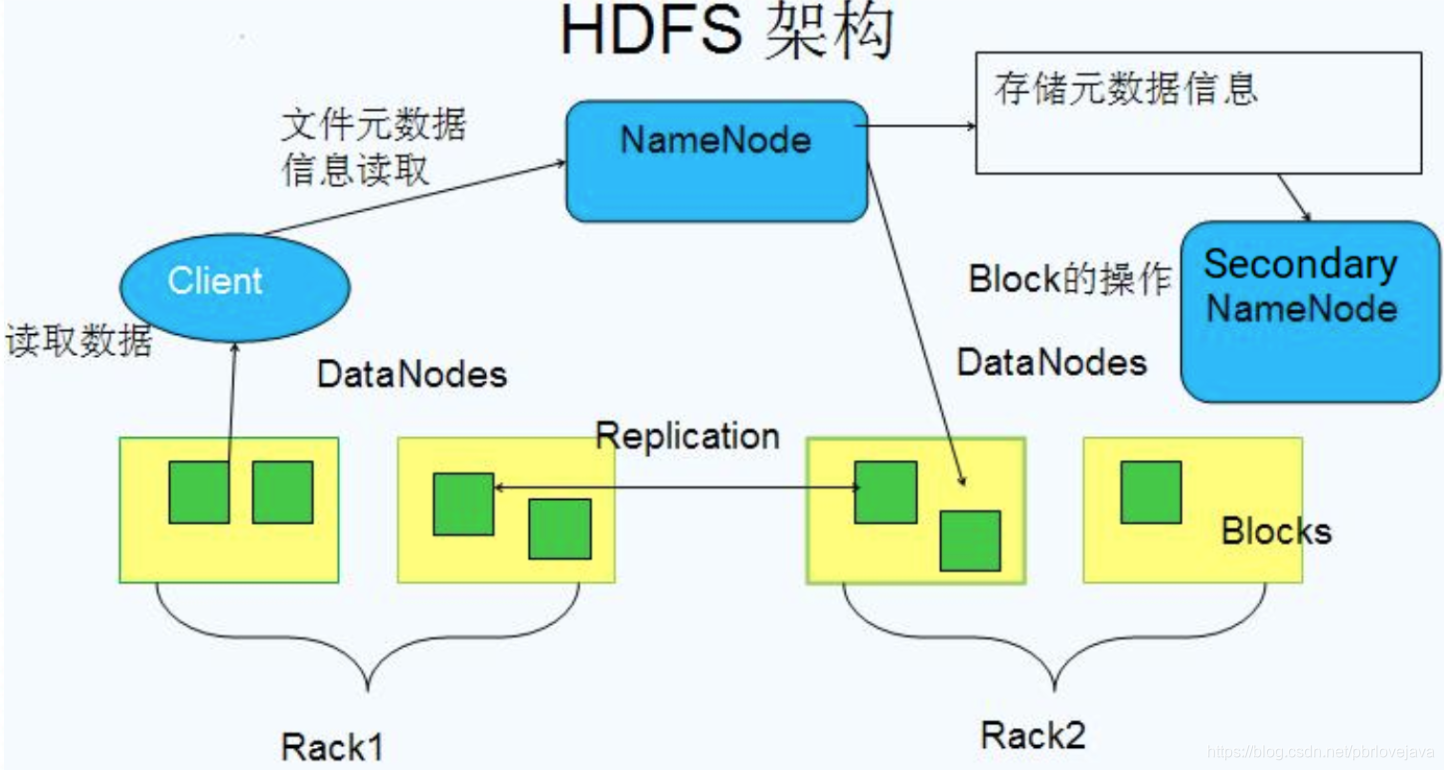
NameNode
- 存储文件的描述元数据,运行时所有数据都保存到内存,整个HDFS可存储的文件数受限于NameNode的内存大小,当NameNode内存无法容纳下描述元数据时则无法继续在HDFS中新增数据
- 一个Block在NameNode中对应一条记录(一般一个Block记录占用150字节),如果是大量的小文件,会消耗大量内存。因此Hadoop建议存储少数的大文件而不是多数的小文件。
- 数据会定时保存到本地磁盘,但不保存block的位置信息,而是由DataNode注册时上报和运行时维护(NameNode中与DataNode相关的信息并不保存到NameNode的文件系统中,而是NameNode每次重启后,动态重建)
- NameNode失效则整个HDFS都失效了,所以要保证NameNode的可用性,NameNode是HDFS系统的入口
Secondary NameNode
因为NameNode是HDFS的入口,当NameNode出现故障时整个HDFS都不可用,所以需要提供一个备份节点,当主NameNode故障时进行转移采用备份NameNode节点,这是一种常见的主从备份机制。而Secondar NameNode就是NameNode的备份,定时与NameNode进行同步,以保障HDFS的可用性。
DataNode
- 保存具体的block数据
- 负责数据的读写操作和复制操作
- DataNode启动时会向NameNode报告当前存储的数据块信息,后续也会定时报告修改信息
- DataNode之间会进行通信,复制数据块,保证数据的冗余性
Block
上文一直提到的Block块也就是HDFS中存储数据的基本单位,默认一个Block为64M,每个DataNode中会根据数据的大小将其切分为不同的Block,每个Block又默认含有两份副本。使用Block的原因是:
- 大的块可以减少磁盘寻道时间
- 减少数据块的数量,每个Block都需在NameNode中注册一个记录,所以块越大则记录越少
2.2、读数据逻辑

HDFS读数据的逻辑如上图所示,过程如下:
- 客户端Client向NameNode发送读取请求
- NameNode返回文件的所有Block和这些Block所在的DataNodes(包括复制节点)
- 客户端Client直接从DataNode中读取数据,如果该DataNode读取失败则从复制节点中读取(如果读取的数据就在本机,则直接读取,否则通过网络读取)
2.3、写数据逻辑
HDFS写数据的逻辑如上图所示,过程如下: 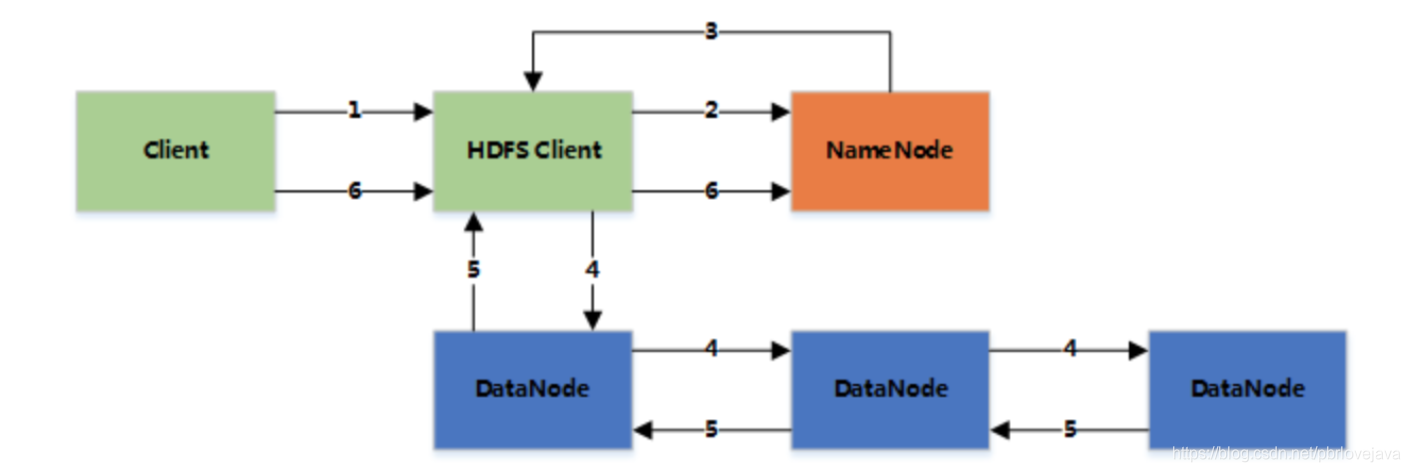
- 客户端Client将文件写入本地磁盘的 HDFS Client 文件中
- 当临时文件大小达到一个 Block 大小时,HDFS Client 通知 NameNode,申请写入文件
- NameNode 在 HDFS 的文件系统中创建一个文件,并把该 Block Id 和要写入的 DataNode 的列表返回给客户端
- 客户端收到这些信息后,将临时文件写入 DataNodes
- 4.1 客户端将文件内容写入第一个 DataNode(一般以 4kb 为单位进行传输)
- 4.2 第一个 DataNode 接收后,将数据写入本地磁盘,同时也传输给第二个 DataNode
- 4.3 依此类推到最后一个 DataNode,数据在 DataNode 之间是通过 pipeline 的方式进行复制的
- 4.4 后面的 DataNode 接收完数据后,都会发送一个确认给前一个 DataNode,最终第一个 DataNode 返回确认给客户端
- 4.5 当客户端接收到整个 block 的确认后,会向 NameNode 发送一个最终的确认信息(ACK机制)
- 4.6 如果写入某个 DataNode 失败,数据会继续写入其他的 DataNode。然后 NameNode 会找另外一个好的 DataNode 继续复制,以保证冗余性
- 4.7 每个 block 都会有一个校验码,并存放到独立的文件中,以便读的时候来验证其完整性 5.文件写完后(客户端关闭),NameNode 提交文件,文件才可见,如果提交前,NameNode 垮掉,那文件也就丢失了
HDFS的使用很简单,熟悉Linux命令的使用者可以快速地上手,以下是HDFS常用的命令整理,注意其他文件和路径名是指HDFS内部的对象,在使用前需要先初始化生产HDFS文件系统并启动:
HDFS是分布式的系统,所以务必会存在若干个服务器节点,各个节点间通过网络进行通信,那么就会存在分布式系统的可靠性问题(CAP或base理论),所以HDFS主要从以下几个方面来保障了系统的分布式可靠性。
3.1、副本冗余
HDFS的通过副本冗余机制来保障数据块Block的冗余,默认一个Block被保存为3份,可通过hdfs-site.xml配置文件进行配置。通过副本冗余机制,使得DataNode出现故障时也不会出现单点问题,只要其他DataNode中存在备份的Block即可继续完成数据操作,当Block恢复后会再继续同步备份。
3.2、机架策略
HDFS在进行副本冗余时,会通过机架策略来选择不同机架的DataNode节点来备份Block,这里的“机架”可以理解为一个局域网内的节点集合,可通过hadoop-site.xml配置文件进行配置,将不同的服务器规划到不同的机架中。机架策略可以避免副本都存在于同一网络之中,因为网络故障通常会在局域网范围内传播,很可能导致同一网络下的其他节点也不可使用,所以需要通过机架策略将副本放到其他局域网中,达到网络隔离的效果。
3.3、心跳机制
NameNode会周期性从DataNode接受心跳信息和Block信息,以检查各个DataNode是否可用,当某个DataNode不可用时则会将其标识为宕机节点,不会对其进行数据写入和读取等I/O操作,当其恢复后会继续连接到NameNode中执行后续的同步操作。
3.4、安全校验
在HDFS启动过程中会进行Block副本数目安全校验,如果Block的副本数目符合规定数目则启动,否则会先进行数据备份,直到Block副本数符合规定的数目才进行启动。
3.5、数据恢复
HDFS在删除文件时,数据其实是放入回收站路径/trash中,而回收站里的文件是可以快速恢复的,可以设置一个时间值,当回收站里文件的存放时间超过了这个值,就被彻底删除,并且释放占用的Block。