最基本指标:查全率R(召回率 Recall rate)、查准率P(Precision rate),计算公式如下:


准确率和召回率是互相影响的,一般情况下查准率高、召回率就低,召回率低、查准率高。在检索中往往要在保证召回率的前提下提高查准率。在对查准率和召回率都要求高时,可以用F-Measure综合考虑他们,当a=1时,就是常见的F1了,F1综合了P和R的结果,当F1较高时则比较说明实验方法比较理想。计算公式如下:

无论是召回率R、查准率P还是F1,都存在有单点值局限性,为了得到 一个能够反映全局性能的指标,引入MAP(mean average precision)。对于P和R,用不同的阀值,可以统计出一组不同阀值下的精确率和召回率,叫做P-R图,如下图所示,两条曲线分布对应了两个检索系统的P-R曲线。虽然两个系统的性能曲线有所交叠。但是以圆点标示的系统的性能在绝大多数情况下要远好于用方块标示的系统。所以P-R曲线更向上突出的系统性能更好,也就是说,P-R曲线与坐标轴之间的面积应当越大越好。MAP即为求P-R曲线与坐标轴包围的面积,理想情况下面积为1。
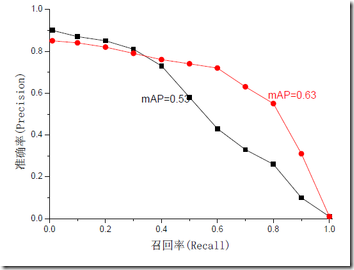

关于上述对MAP的解释,博主仔细翻看了周志华老师的《机器学习》,虽然我对P-R曲线面积的作用描述是没问题的,但是并未发现书中对P-R曲线的面积有过称为MAP的情况。而博主在论文中看到的MAP的使用,应该属于我下一种的解释。两者之间有无关系,我会继续关注。
MAP是评估检索策略效果的方式之一,除了考虑召回结果的整体准确率之外,MAP也考量召回结果条目的顺序。在了解MAP之前,我们要先了解Prec@K和AP@K的概念。
Prec@K表示设定一个阈值K,在检索结果到第K个正确召回为止,排序结果的相关度。假设某次的检索结果如下:

在这个案例中Prec@1=1、Prec@2=2/3、Prec@3=3/5。但是,Prec@K也只能表示单点的策略效果,我们需要使用AP@K体现策略的整体效果。
Average Precision@K是指到第K个正确的召回为止,从第一个正确召回到第K个正确召回的平均正确率。下图为两种K=6的排序策略的结果。  根据经验,我们容易判断出第一种排序好于第二种。对于结果1,AP=(1.0+0.67+0.75+0.8+0.83+0.6)/6=0.78,对于结果2,AP=(0.5+0.4+0.5+0.57+0.56+0.6)/6=0.52,可以看到,效果优的策略1的AP@K值大于效果劣的策略2。
根据经验,我们容易判断出第一种排序好于第二种。对于结果1,AP=(1.0+0.67+0.75+0.8+0.83+0.6)/6=0.78,对于结果2,AP=(0.5+0.4+0.5+0.57+0.56+0.6)/6=0.52,可以看到,效果优的策略1的AP@K值大于效果劣的策略2。
对于一次查询,AP值可以判断优劣,但是如果涉及到一个策略在多次查询的效果,我们需要引入另一个概念MAP(Mean Average Precision),简单的说,MAP的计算的是搜索查询结果AP值的均值。如上图如果表示的是一个策略下,两次不同的搜索的结果,则MAP = (0.78+0.52)/2。
TF-IDF是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。英文为Term Frequency-Inverse document Frequency, 意思是词频-逆文件频率。它的思想在一个文章集中,如果一个词语在一篇文章中出现次数越多(TF越大), 同时在所有文档中出现次数越少(IDF越大), 越能够代表该文章。它由词频TF,逆向文件频率文件IDF两部分组成,表达式为TF-IDF = TF * IDF。例如,查询词X对于文章C的重要程度,它的TF和IDF的计算如下:
浏览该页面的概率,是谷歌搜索的排名算法。它通过网站外部链接和内部链接的数量和质量来评价网站的价值,PR越高,网站越受欢迎,越重要,排名也越高。
简单的例子如下图所示,图中每个节点表示一个网页,箭头表示网页链接方向。页面x的page rank为PR(x),那么PR(C)= PR(A)/2 + PR(B)/1。
问题在于,要计算PR(C),就要先知道PR(A)和PR(B),要知道PR(A)和PR(B)又要先知道PR(C)。这就是一个先有鸡还是先有蛋的问题 了,在计算机学习的时候不止一次碰到过这种纠结的问题,不过解决方法我碰到过的都是先按照一定方法给定一个初值。[1] Google的两个创始人拉里佩奇和谢耳盖把这个问题变成一个二维矩阵相乘的问题,并且用迭代的方法解决了这个问题。他们先假定所有网页的排名是相同的,并且根据这个初始值,算出各个网页的第一次迭代的排名,然后再根据第一次迭代排名算出第二次的排名。他们两人从理论上证明了不论初始值如何选取,这种算法都将能够保证了网页排名的估计值能够收敛到它们就有的真实值。值得一提的是,这种算法的执行是完全没有任何人工干预的。
BoW模型可认为是一种统计直方图。在文本检索和处理应用中, 可以通过该模型很方便的计算词频。有如下例子: S1:more ugly less bug is ugly. S2:more ugly less bug have bug. 根据上述S1、S2中出现的单词, 我们能构建出一个字典,{1:"more",2:"ugly",3:"less",4:"bug",5:"is",6:"have"}。用这个字典可以构建出下面两个向量。 S1:(1,1,1,1,1,0)。S2:(1,1,1,2,0,1)。这两个向量共包含6个元素, 其中第i个元素表示字典中第i个单词在句子中出现的次数,在文本检索和处理应用中, 可以通过该模型很方便的计算词频。
BM25算法通常用来作搜索相关评分。主要思想是对查询词进行分词成Term,标记为qi。然后对于每个搜索结果D,计算每个qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。BM25是一个bag-of-words模型的检索函数,基于在各文件中出现的查询词项计算相关性评分。它不像Term Proximity检索查询词在文件中内在的联系。
BM25算法的一般性公式如下:
其中,Q表示Query。qi表示Q解析之后的一个Term。d表示一个搜索结果文档。Wi表示语素qi的权重,用IDF计算。R(qi,d)表示词qi与文档d的相关性得分。其实就是计算一个query里面所有词和文档的相关度,然后在把分数做累加操作,而每个词的相关度分数主要还是受到TF-IDF的影响。
更完整的BM25公式如下:
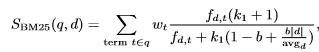
其中k1,b都是调节因子,|d|是文档d的长度,avgd是这个文档集的平均文档长度。fd,t是词t在文档d中出现的次数wt是用IDF计算而来的。
总结一下影响BM25公式的因数主要有三点:1、IDF越高分数越高。2、TF越高分数越高。3 如果查询到的文档长度相对文档集的平均长度越长,则分数越低。

可以很明显看出文档2与查询词的相关性要比文档1好,但是只用bag-of-words则很难保证这一点,查询词项在文档中出现的顺序,和词之间的距离同样是影响相关性的重要因素。所以要引入Proximity保证查询词之间的相近度。可以有以下几种方式:
这种方式主要是计算 Term 之间距离作为 Proximity 得分。主要分为 Span-based和Distance aggregation两类。假设现在有文档 D = t1, t2, t1, t3, t5, t4, t2, t3, t4,接下来通过基于文档D的举例说明,解释两类算法。
1、Span :在文档中可以覆盖所有term的最小距离称为 Span , 需要包含所有重复的term 。比如Query=t1,t2,则这个查询的Span=6。
2、MinCover :在文档中可以覆盖所有term的最小距离称为 MinCover , 每个term至少被包含一次 。比如这里的Q=t1,t2,则查询的MinCover=1 3、Distance aggregation:这种方式计算的最近单元是计算一个term pair的最小距离,使用Dis(ti,tj;D)来表示。先计算两两之间的距离,再聚集起来。 4、MinDist(Minimum pair distance) :计算所有pair的最小距离的最小值。比如Q=t1,t2,t3,则MinDist=min(1,2,3)=1。 5、AveDist(Average pair distance) :计算所有pair的最小距离的平均值,比如Q=t1,t2,t3,则AveDist=(1+2+3)/3=2 AveDist=(1+2+3)/3=2。 6、MaxDist(Maximum pair distance) :与 MinDist 正好相反,它是求最大值。比如Q=t1,t2,t3,则MaxDist=max(1,2,3)=3。
但是,研究显示并不是所有查询都要用上Proximity measures,有些查询不适合用。如果对不适合用Proximity的查询使用的话,不仅会增加计算时间,还有可能产生差的排名。
在解释倒排索引之前,我们先了解一下什么是正向索引(forward index),以及为什么不用正向索引要使用倒排索引。
在搜索引擎中每个文件都对应一个文件ID,文件内容被表示为一系列关键词的集合(实际上在搜索引擎索引库中,关键词也已经转换为关键词ID)。例如“文档1”经过分词,提取了数个关键词,每个关键词都会记录它在文档中的出现次数和出现位置,得到正向索引的结构如下:
“文档”ID;单词1:出现次数,出现位置列表;单词2:出现次数,出现位置列表;......
用正向索引,搜索关键词时,需要扫描库中的所有文档,对每个文档中的关键词进行搜索,因为互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。因此引入了倒排索引。
正向索引是文件ID对应到关键词的映射。倒排索引则相反,是关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词,倒排索引的结构如下:
“关键词”:“文档1”的ID,“文档2”的ID,......
正向最大匹配法是分词算法的其中一种,它是按照一定的策略将待分析的汉字串与词典中的词条进行配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。算法的核心就是从左到右搜索,然后找到最长的字典分词。算法使用时首先要定义一个最大长度,下面的例子中最大长度为5。
例子:南航是一所知名大学
过程如下: 南航是一所 南航是一 南航是 南航 ----> 得到一个词–南航 是一所知名 是一所知 是一所 是一 是 ----> 得到一个词–是 一所知名大 一所知名 一所知 一所 ----> 得到一个词–一所 知名大学 知名大 知名 ---->得到一个词– 知名 大学 ---->得到一个词– 大学 最后正向最大匹配的结果是: /南航/是/一所/知名/大学
Term:信息检索的第一步是对文档进行分词。这些分词也叫做Term。Term表示文本中的一个词语,是搜索的最小单元。
posting lists:倒排记录表
query:查询条件
Inverted Index:倒排索引
term proximity(TP) :近邻词得分



